tcpdump在内核中是如何工作的
背景
在使用Cilium的过程中,我们发现很多情况下看到流量已经打通,但使用tcpdump抓包却看不到任何包经过的痕迹。本文尝试对tcpdump在kernel中的工作过程一探究竟。
内核对网络数据的处理
在分析tcpdump的工作原理前,需要了解kernel对网络数据的处理过程。
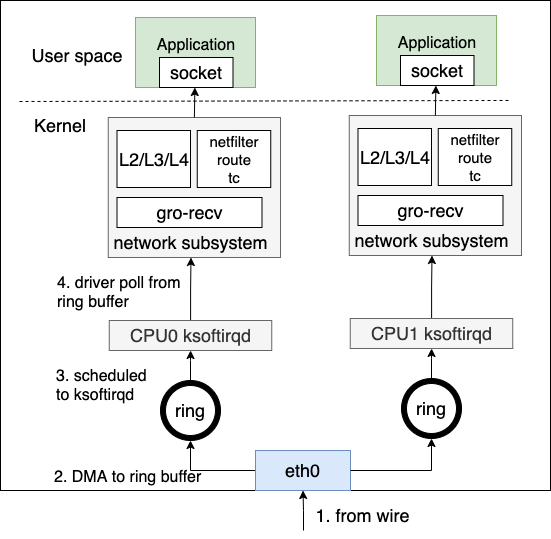
总体来说,当物理网卡(NIC)收到物理线路上的数据帧时
- NIC以DMA方式把数据帧写入预先分配的ring buffer中
- 触发硬中断,通知CPU有网络数据需要接收
- CPU收到后,触发软中断 softirq
- 调用driver注册的poll函数从ring buffer中poll出数据帧
- 进入网络子系统处理,经过tc/netfilter/route等子系统,处理相关的L2/L3/L4协议
- 发给对应的用户态注册的socket
初始化
内核需要先完成初始化工作来支撑之后的数据包处理,包括
- 驱动初始化
- 软中断线程初始化
- 协议栈处理函数初始化
我们将在下一篇文章中详细解读驱动初始化和软中断线程初始化。这篇文章中,协议栈处理函数初始化是我们关注的重点。
以IP为例,IPv4和IPv6的初始化如下
// af_inet.c
static int __init inet_init(void)
{
...
dev_add_pack(&ip_packet_type);
}
static struct packet_type ip_packet_type __read_mostly = {
// Register ETH_P_IP & ip_rcv for IPv4
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
.list_func = ip_list_rcv,
};
// af_inet6.c
static struct packet_type ipv6_packet_type __read_mostly = {
// Register ETH_P_IPV6 & ip_rcv for IPv6
.type = cpu_to_be16(ETH_P_IPV6),
.func = ipv6_rcv,
.list_func = ipv6_list_rcv,
};
static int __init ipv6_packet_init(void)
{
dev_add_pack(&ipv6_packet_type);
return 0;
}
在dev_add_pack中,协议和对应handler分别被加入到ptype_all(ETH_P_ALL)或ptype_base(其他协议)。
// dev.c
void dev_add_pack(struct packet_type *pt)
{
struct list_head *head = ptype_head(pt);
spin_lock(&ptype_lock);
list_add_rcu(&pt->list, head);
spin_unlock(&ptype_lock);
}
static inline struct list_head *ptype_head(const struct packet_type *pt)
{
if (pt->type == htons(ETH_P_ALL))
return pt->dev ? &pt->dev->ptype_all : &ptype_all;
else
return pt->dev ? &pt->dev->ptype_specific :
&ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK];
}
// if_ether.h
#define ETH_P_ALL 0x0003 /* Every packet (be careful!!!) */
接收端处理
在接收侧,__netif_receive_skb_core先判断ptype_all中是否有sniffer注册了ETH_P_ALL类型的协议,如果有,则送到对应的handler处理。再根据数据包的类型,将skb送给注册协议的handler,比如ETH_P_IP等。
//dev.c
static int __netif_receive_skb_core(struct sk_buff **pskb, bool pfmemalloc,
struct packet_type **ppt_prev)
{
...
// XDP processing
// ret2 = do_xdp_generic(rcu_dereference(skb->dev->xdp_prog), skb);
// deliver skb to ptype_all
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
list_for_each_entry_rcu(ptype, &skb->dev->ptype_all, list) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
// tc handling
// skb = sch_handle_ingress(skb, &pt_prev, &ret, orig_dev, &another);
...
// deliver skb to ptype_base
if (likely(!deliver_exact)) {
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, &ptype_base[ntohs(type) & PTYPE_HASH_MASK]);
}
}
查看libpcap的代码,可以看到pcap使用的正是ETH_P_ALL协议,并注册了AF_PACKET类型的socket。
//libpcap-linux.c
static int pcap_protocol(pcap_t *handle)
{
int protocol;
protocol = handle->opt.protocol;
if (protocol == 0)
protocol = ETH_P_ALL;
return htons(protocol);
}
static int iface_bind(int fd, int ifindex, char *ebuf, int protocol)
{
...
sll.sll_family = AF_PACKET;
sll.sll_ifindex = ifindex < 0 ? 0 : ifindex;
sll.sll_protocol = protocol;
...
}
在kernel中,注册socket会对应的增加一个proto的处理,对应的skb会发送给该协议相关的所有socket。这也就是为什么tcpdump可以在用户态收到网卡抓到包的原因。
// af_packet.c
static void __register_prot_hook(struct sock *sk)
{
struct packet_sock *po = pkt_sk(sk);
if (!po->running) {
if (po->fanout)
__fanout_link(sk, po);
else
dev_add_pack(&po->prot_hook);
sock_hold(sk);
po->running = 1;
}
}
static void register_prot_hook(struct sock *sk)
{
lockdep_assert_held_once(&pkt_sk(sk)->bind_lock);
__register_prot_hook(sk);
}
发送端处理
接收端的方式也是一样的。协议栈处理完后,__dev_queue_xmit做最后的发送,先经过tc处理,再经过ETH_P_ALL协议的处理,发送给对应的处理函数。
// dev.c
static int __dev_queue_xmit(struct sk_buff *skb, struct net_device *sb_dev)
{
...
// tc processing
//skb = sch_handle_egress(skb, &rc, dev);
skb = dev_hard_start_xmit(skb, dev, txq, &rc);
}
dev_hard_start_xmit
| dev_queue_xmit_nit
| xmit_one
| dev_queue_xmit_nit
void dev_queue_xmit_nit(struct sk_buff *skb, struct net_device *dev)
{
list_for_each_entry_rcu(ptype, ptype_list, list) {
...
if (pt_prev) {
deliver_skb(skb2, pt_prev, skb->dev);
pt_prev = ptype;
continue;
}
}
}