Tcpdump Deep Dive - How Tcpdump works in the kernel
Background
While using Cilium, we have observed that in some cases, despite successful pinging, tcpdump fails to capture any packets. This article aims to look into the mechanics of tcpdump in the kernel.
Network processing by the kernel
Before diving deep, we need to understand how the kernel processes network traffic.
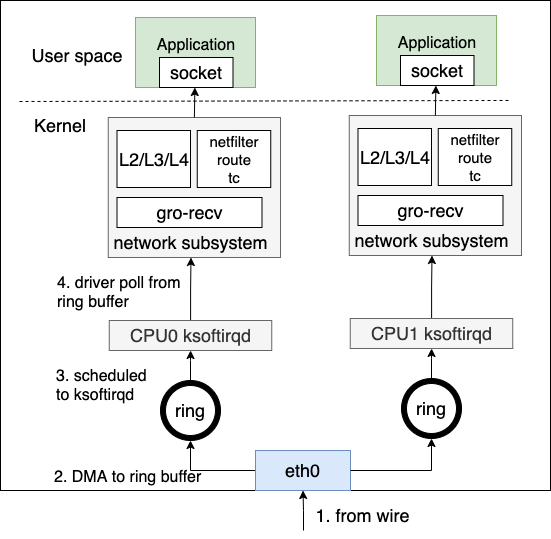
When a network interface card (NIC) receives data frames from the wire
- It utilizes direct memory access (DMA) to write the data frame into a pre-allocated ring buffer.
- This triggers a hard interrupt to notify the CPU that there is network data to receive.
- Upon receiving the interrupt, the CPU triggers a soft interrupt
- It calls the driver’s registered poll function to poll the data frames from the ring buffer.
- The data frames enter the network subsystem, passing through sub-systems such as tc, netfilter, and route for L2/L3/L4 protocols.
- Finally, the data frames are sent to the corresponding user space registered sockets.
Initialization
The kernel needs to complete the initialization to support the subsequent packet processing, including:
- Driver initialization
- Soft interrupt thread initialization
- Initialization of network stack processing functions
This article only focuses on the initialization of network stack processing functions.
Take IP as an example, the initialization processes of IPv4 and IPv6 are as follow.
// af_inet.c
static int __init inet_init(void)
{
...
dev_add_pack(&ip_packet_type);
}
static struct packet_type ip_packet_type __read_mostly = {
// Register ETH_P_IP & ip_rcv for IPv4
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
.list_func = ip_list_rcv,
};
// af_inet6.c
static struct packet_type ipv6_packet_type __read_mostly = {
// Register ETH_P_IPV6 & ip_rcv for IPv6
.type = cpu_to_be16(ETH_P_IPV6),
.func = ipv6_rcv,
.list_func = ipv6_list_rcv,
};
static int __init ipv6_packet_init(void)
{
dev_add_pack(&ipv6_packet_type);
return 0;
}
In function dev_add_pack, protocols and corresponding handlers are added to ptype_all (ETH_P_ALL) or ptype_base (other protocols).
// dev.c
void dev_add_pack(struct packet_type *pt)
{
struct list_head *head = ptype_head(pt);
spin_lock(&ptype_lock);
list_add_rcu(&pt->list, head);
spin_unlock(&ptype_lock);
}
static inline struct list_head *ptype_head(const struct packet_type *pt)
{
if (pt->type == htons(ETH_P_ALL))
return pt->dev ? &pt->dev->ptype_all : &ptype_all;
else
return pt->dev ? &pt->dev->ptype_specific :
&ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK];
}
// if_ether.h
#define ETH_P_ALL 0x0003 /* Every packet (be careful!!!) */
RX side processing
At the RX side, __netif_receive_skb_core first iterates ptype_all sniffers and delivers skb to its handler. Then according to the packet type (e.g., ETH_P_IP), it delivers skb to the handlers registered to ptype_base.
//dev.c
static int __netif_receive_skb_core(struct sk_buff **pskb, bool pfmemalloc,
struct packet_type **ppt_prev)
{
...
// XDP processing
// ret2 = do_xdp_generic(rcu_dereference(skb->dev->xdp_prog), skb);
// deliver skb to ptype_all
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
list_for_each_entry_rcu(ptype, &skb->dev->ptype_all, list) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
// tc handling
// skb = sch_handle_ingress(skb, &pt_prev, &ret, orig_dev, &another);
...
// deliver skb to ptype_base
if (likely(!deliver_exact)) {
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, &ptype_base[ntohs(type) & PTYPE_HASH_MASK]);
}
}
Checking libpcap’s source code, we find it uses ETH_P_ALL as the protocol.
//libpcap-linux.c
static int pcap_protocol(pcap_t *handle)
{
int protocol;
protocol = handle->opt.protocol;
if (protocol == 0)
protocol = ETH_P_ALL;
return htons(protocol);
}
static int iface_bind(int fd, int ifindex, char *ebuf, int protocol)
{
...
sll.sll_family = AF_PACKET;
sll.sll_ifindex = ifindex < 0 ? 0 : ifindex;
sll.sll_protocol = protocol;
...
}
Back to the Linux kernel, we provide the protocol and handler while creating a socket. That’s why tcpdump can dump the packets from the NIC.
Note that XDP hook point is ahead of ETH_P_ALL processing. That’s why in some cases we miss packet capture in Cilium. Data is redirected at the first entry point.
// af_packet.c
static void __register_prot_hook(struct sock *sk)
{
struct packet_sock *po = pkt_sk(sk);
if (!po->running) {
if (po->fanout)
__fanout_link(sk, po);
else
dev_add_pack(&po->prot_hook);
sock_hold(sk);
po->running = 1;
}
}
static void register_prot_hook(struct sock *sk)
{
lockdep_assert_held_once(&pkt_sk(sk)->bind_lock);
__register_prot_hook(sk);
}
TX side processing
After the network stack, the last step is __dev_queue_xmit. dev_queue_xmit_nit iterates every ETH_P_ALL related sockets and delivers to the handler.
// dev.c
static int __dev_queue_xmit(struct sk_buff *skb, struct net_device *sb_dev)
{
...
// tc processing
//skb = sch_handle_egress(skb, &rc, dev);
skb = dev_hard_start_xmit(skb, dev, txq, &rc);
}
dev_hard_start_xmit
| dev_queue_xmit_nit
| xmit_one
| dev_queue_xmit_nit
void dev_queue_xmit_nit(struct sk_buff *skb, struct net_device *dev)
{
list_for_each_entry_rcu(ptype, ptype_list, list) {
...
if (pt_prev) {
deliver_skb(skb2, pt_prev, skb->dev);
pt_prev = ptype;
continue;
}
}
}
Conclusion
We dive deep into source code to better understand how tcpdump works. For short takeaways,
- RX side: XDP ->
Tcpdump-> TC -> network stack - TX side: network stack -> TC ->
Tcpdump