Cilium Datapath Deep Dive 1 - Basic Connectivity
Overview
With the rapid development of BPF/eBPF technology, Cilium is regarded as the most promising network solution in the Kubernetes ecosystem. Leveraging the flexible, efficient, and functionally/data-separate features of BPF, Cilium is officially supported by several public clouds.
Most traditional Kubernetes CNI plugins are based on Linux kernel networking solutions, such as Flannel based on tunneling (with backend options like vxlan and user-space UDP processes), and Calico based on routing (L2 networks or BGP). When using these CNI plugins, we can easily determine the actual path of packets and how they are forwarded using kernel-provided toolsets such as iproute2/tcpdump. However, when using Cilium, it is often difficult to capture packets and obtain any statistical information, leaving one perplexed.
This article attempts to summarize Cilium’s packet processing logic through analysis of existing tools and source code.
Backgroud
Important BPF hook points
- XDP: the earliest processing point for data packets received by the driver of a network device, even before the skb struct created. XDP has three modes: native, offload, and generic. When the network card does not support offload, it is best to use the native mode supported by a high version of the kernel. When the native mode is not supported, the generic mode can be used as a simulation. XDP is suitable for DDoS protection, firewall, and other functions.
Take linux igb driver source code as example, we can see where XDP works.
// linux source code: igb_main.c
static int igb_clean_rx_irq(struct igb_q_vector *q_vector, const int budget)
{
...
/* retrieve a buffer from the ring */
if (!skb) {
unsigned char *hard_start = pktbuf - igb_rx_offset(rx_ring);
unsigned int offset = pkt_offset + igb_rx_offset(rx_ring);
// XDP program initiates
xdp_prepare_buff(&xdp, hard_start, offset, size, true);
#if (PAGE_SIZE > 4096)
/* At larger PAGE_SIZE, frame_sz depend on len size */
xdp.frame_sz = igb_rx_frame_truesize(rx_ring, size);
#endif
// <=== XDP program runs here ===>
skb = igb_run_xdp(adapter, rx_ring, &xdp);
}
...
}
In this article, we use the default Cilium configuration (disabled policies). No BPF programs were attached to XDP. We will introduce policies in later articles.
- TC: the initial processing point of the network stack. It is heavily used in Cilium and is closely related to basic connectivity. We will focus on TC in particular.
// linux source code: dev.c
__netif_receive_skb_core
| list_for_each_entry_rcu(ptype, &ptype_all, list) {...} // packet capture
| do_xdp_generic // handle generic xdp
| sch_handle_ingress // tc ingress
| tcf_classify
| __tcf_classify // bpf program is working here
Cilium Datapath
In this part, We analyze how Cilium datapath is working. To make the cluster network independent of the underlay network, tunnel mode is used.
Experimental setup:
Ubuntu 21.04
Linux kernel 5.10
Cilium 1.12
Others: default configuration (kube-proxy-replacement: disabled; tunnel: vxlan)
After deployment, each node has a veth pair cilium_host/cilium_net and a vxlan device cilium_vxlan. A veth device lxcXXXX on node corresponds to eth0 inside each pod. Cilium uses default cluster-scope IPAM mode to assign a PodCIDR for each node, and the pods on that node will get an IP within that CIDR. The cilium_host on each node has an IP that serves as the gateway for all Pods on that node.
podCIDR is recorded in resource CiliumNode.
# kubectl get ciliumnodes cilium-worker -o yaml
apiVersion: cilium.io/v2
kind: CiliumNode
...
spec:
ipam:
podCIDRs:
- 10.0.1.0/24
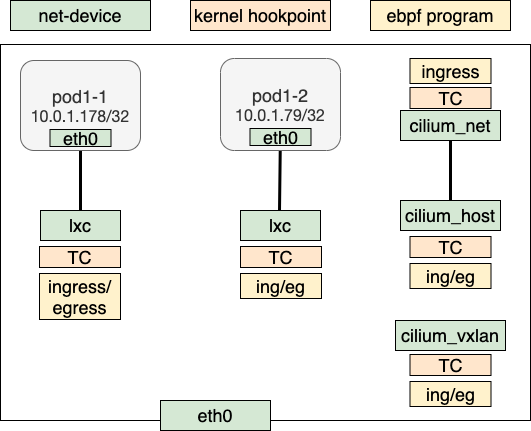
The below diagrams describe how Cilium’s datapath implemented the basic connectiviy.
BPF prgram hook points:
lxc(pod eth0’s peer veth):TC ingress/TC egresscilium_host(veth netdev): TC ingress/egresscilium_net(cilium_host’s peer veth): TC ingresscilium_vxlan(vxlan netdev): TC ingress/egress
pod to pod on the same node
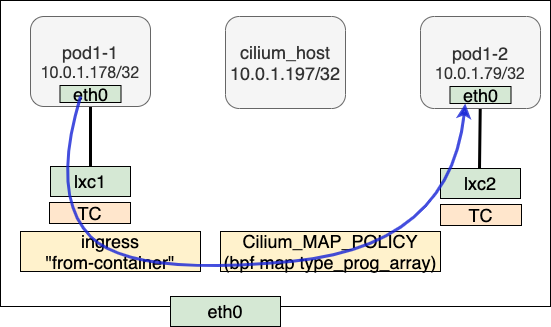
Take pod1-1 to pod1-2 TX as an example. The IP address of pod1-1 is 10.0.1.178, and the destination IP address of pod1-2 is 10.0.1.79. Although their IP addresses are from the same CIDR, the network mask is 32. So packets need to go through the gateway. On that node, cilium_host 10.0.1.197 is the gateway for all pods.
// on pod1-1
/ # ip r
default via 10.0.1.197 dev eth0
10.0.1.197 dev eth0 scope link
Let’s first analyze the processing of ARP. pod1-1 sends an ARP request to the gateway, with the destination IP address of 10.0.1.197 (cilium_host). Note that the source MAC address of the response received here is not from the cilium_host, but from lxc1. Cilium uses a technique similar to arp_proxy to achieve layer 3 forwardings. The reason why it is similar to arp_proxy is that arp_proxy is not enabled in the kernel, but the effects are done by the BPF program attached to lxc1.
// bpf_lxc.c
__section("from-container")
int handle_xgress(struct __ctx_buff *ctx)
{
...
switch (proto) {
...
#elif defined(ENABLE_ARP_RESPONDER)
case bpf_htons(ETH_P_ARP):
ep_tail_call(ctx, CILIUM_CALL_ARP); // tail_call tail_handle_arp
ret = DROP_MISSED_TAIL_CALL;
break;
#endif /* ENABLE_ARP_RESPONDER */
...
}
__section_tail(CILIUM_MAP_CALLS, CILIUM_CALL_ARP)
int tail_handle_arp(struct __ctx_buff *ctx)
{
union macaddr mac = NODE_MAC; // dst mac is populated with NODE_MAC
...
return arp_respond(ctx, &mac, tip, &smac, sip, 0);
}
static __always_inline int
arp_respond(struct __ctx_buff *ctx, union macaddr *smac, __be32 sip,
union macaddr *dmac, __be32 tip, int direction)
{
...
return ctx_redirect(ctx, ctx_get_ifindex(ctx), direction); // redirect skb to src iface
...
}
Let’s look at regular IPv4 forwarding in Cilium. The ctx (i.e., skb) goes through a series of tail calls and is eventually handled by handle_ipv4_from_lxc.
Call stack:
// bpf_lxc.c
handle_xgress(struct __ctx_buff *ctx)
| ep_tail_call(ctx, CILIUM_CALL_IPV4_FROM_LXC)
| tail_handle_ipv4(struct __ctx_buff *ctx)
| __tail_handle_ipv4(ctx)
| tail_handle_ipv4_cont(struct __ctx_buff *ctx)
| handle_ipv4_from_lxc(ctx, &dst_id)
| lookup_ip4_endpoint(ip4) // get local endpoint (pod or host)
| ipv4_local_delivery(...)
| ipv4_l3(ctx,...) // ttl-1 & update mac header
| tail_call_dynamic(ctx, &POLICY_CALL_MAP, ep->lxc_id) // jump to destination pod's bpf program for policy enforcement
| handle_policy(...)
| tail_ipv4_ct_ingress_policy_only(...)
| tail_ipv4_policy(...)
| ipv4_policy(...)
| redirect_ep(...) // redirect to dst iface
After processing of CT and others, lookup_ip4_endpoint looks up BPF map cilium_lxc and gets the endpoint information corresponding to its IP.
root@cilium-worker2:/home/cilium# cilium map get cilium_lxc
Key Value State Error
10.0.1.51:0 id=51 flags=0x0000 ifindex=8 mac=AE:3A:52:A3:EC:B3 nodemac=0A:5A:DE:B8:D8:F4 sync
10.0.1.9:0 id=2389 flags=0x0000 ifindex=10 mac=A6:0D:28:CA:4A:85 nodemac=5A:01:4A:68:C4:C4 sync
10.0.1.18:0 id=2400 flags=0x0000 ifindex=12 mac=EE:9D:C0:B1:94:34 nodemac=12:3F:87:06:72:79 sync
10.0.1.178:0 id=1272 flags=0x0000 ifindex=14 mac=66:FE:F8:92:BF:AF nodemac=5A:03:C6:E1:49:D2 sync
10.0.1.79:0 id=436 flags=0x0000 ifindex=16 mac=32:ED:0B:F8:18:E9 nodemac=C2:8B:75:D9:5F:EC sync
In the ipv4_local_delivery function, the IP packet is first processed at layer 3, which includes decrementing the TTL and updating the MAC address. By tail call, a packet is sent to the destination lxc to perform NAT and policy enforcement (there is currently no policy in our deployment). Finally, the packet is passed to the destination endpoint via redirect_ep.
It should be noted that the behavior of redirect_ep depends on a macro definition that determines whether the packet is sent directly to the destination lxc or eth0 interface within the pod. The kernel version affects the actual forwarding logic. With kernel version 5.10, the function directly calls ctx_redirect_peer to send the packet to the final destination pod1-2’s eth0.
The BPF program on the RX side is attached to the egress direction of the lxc. The receiving side also calls ipv4_policy to perform the redirect. However, our deployment only focuses on connectivity.
// bpf_lxc.c
__section("to-container")
int handle_to_container(struct __ctx_buff *ctx)
{
...
case bpf_htons(ETH_P_IP):
ep_tail_call(ctx, CILIUM_CALL_IPV4_CT_INGRESS);
ret = DROP_MISSED_TAIL_CALL;
break;
...
}
// Call stack
| tail_ipv4_to_endpoint
| ipv4_policy
| redirect_ep(ctx, ifindex, from_host) // redirect to dst iface
pod to pod on different nodes
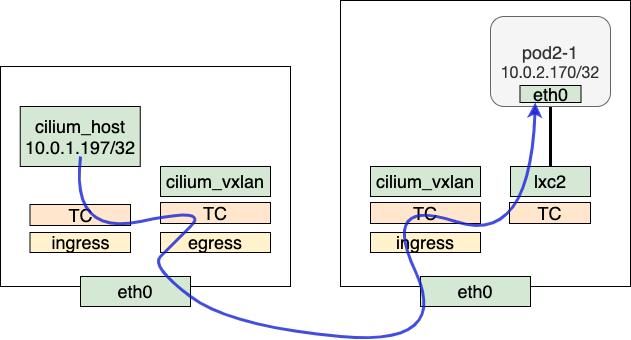
cilium_vxlan encapsulates packets from one pod to vxlan and sends to the other pod on a remote node. Taking the example of communication from pod1-1 to pod2-1, the TX phase follows a part of a similar process as within the same node. However, upon entering handle_ipv4_from_lxc, the BPF map cilium_ipcache is queried for the destination IP’s corresponding tunnel point. If the tunnel point is on a remote node, the process enters encap_and_redirect_lxc, where the original packet from the pod is encapsulated. The encapsulation process populates the tunnel key, remote IP, VNI ID, and other information. Then the packet is redirected to cilium_vxlan and the remaining processing is handled by the kernel vxlan and sent to the destination node via the stack.
root@cilium-worker:/home/cilium# cilium map get cilium_ipcache
Key Value State Error
10.0.2.158/32 identity=13789 encryptkey=0 tunnelendpoint=172.18.0.5 sync
10.0.1.214/32 identity=19140 encryptkey=0 tunnelendpoint=172.18.0.5 sync
10.0.1.213/32 identity=62536 encryptkey=0 tunnelendpoint=0.0.0.0 sync
0.0.0.0/0 identity=2 encryptkey=0 tunnelendpoint=0.0.0.0 sync
172.18.0.4/32 identity=1 encryptkey=0 tunnelendpoint=0.0.0.0 sync
10.0.1.116/32 identity=9049 encryptkey=0 tunnelendpoint=0.0.0.0 sync
Call stack:
// bpf_lxc.c
handle_xgress(struct __ctx_buff *ctx)
| ep_tail_call(ctx, CILIUM_CALL_IPV4_FROM_LXC)
| tail_handle_ipv4(struct __ctx_buff *ctx)
| __tail_handle_ipv4(ctx)
| tail_handle_ipv4_cont(struct __ctx_buff *ctx)
| handle_ipv4_from_lxc(ctx, &dst_id)
| encap_and_redirect_lxc(...) // tunnel_endpoint is fetched from cilum_ipcache map
| __encap_and_redirect_with_nodeid(...)
| __encap_with_nodeid(...)
| ctx_redirect(ctx, ENCAP_IFINDEX, 0) // redirect to vxlan netdev
In RX side, cilium_vxlan receives packets from the wire. After decapsulation by vxlan device, inner packets enter tc ingress ("from-overlay") and are processed by the attached BPF program.
// bpf_overlay.c
__section("from-overlay")
int from_overlay(struct __ctx_buff *ctx)
{
...
case bpf_htons(ETH_P_IP):
#ifdef ENABLE_IPV4
ep_tail_call(ctx, CILIUM_CALL_IPV4_FROM_OVERLAY);
ret = DROP_MISSED_TAIL_CALL;
...
}
__section_tail(CILIUM_MAP_CALLS, CILIUM_CALL_IPV4_FROM_OVERLAY)
int tail_handle_ipv4(struct __ctx_buff *ctx)
{
__u32 src_identity = 0;
int ret = handle_ipv4(ctx, &src_identity);
...
}
Within handle_ipv4, ipcache_lookup4 is called to look up the local identity in the BPF map cilium_ipcache. The function then calls ipv4_local_delivery to forward packets to local interface. Since the call stack of ipv4_local_delivery is the same as that described in the first section, it will not be elaborated on further here.
RX call stack:
// bpf_overlay.c
| tail_handle_ipv4(struct __ctx_buff *ctx)
| handle_ipv4(ctx, &src_identity)
| ipcache_lookup4(...) // get dest identity
| ipv4_local_delivery(...) // deliver to local identity, same steps with previous call stack
node to pod
Take “node to a remote pod” as an example. For TX side, in a node we can see cilium_host is the next hop of all podCIDR. node to pod is actually cilium_host to remote pod.
root@cilium-worker2:/home/cilium# ip r
default via 172.18.0.1 dev eth0
10.0.0.0/24 via 10.0.1.197 dev cilium_host src 10.0.1.197 mtu 1450
10.0.1.0/24 via 10.0.1.197 dev cilium_host src 10.0.1.197
10.0.2.0/24 via 10.0.1.197 dev cilium_host src 10.0.1.197 mtu 1450
10.0.1.197 dev cilium_host scope link
172.18.0.0/16 dev eth0 proto kernel scope link src 172.18.0.3
The whole process is similar to pod-to-pod. Call stack:
// bpf_host.c
handle_netdev(struct __ctx_buff *ctx, const bool from_host)
| do_netdev(ctx, proto, from_host)
| tail_handle_ipv4_from_host(struct __ctx_buff *ctx)
| tail_handle_ipv4(...)
| handle_ipv4(...)
| encap_and_redirect_with_nodeid(...) // encap and send to remote tunnel endpoint
Host RX is also similar to pod-to-pod. After received by cilium_vxlan, we look up BPF map cilium_lxc and check if endpoint is local cilium_host. If yes, redirect to it.
// bpf_overlay.c
| tail_handle_ipv4(struct __ctx_buff *ctx)
| handle_ipv4(ctx, &src_identity)
| ep = lookup_ip4_endpoint(ip4) // look up endpoint from cilium_lxc
| if (ep->flags & ENDPOINT_F_HOST)
| goto to_host
| to_host:
| ipv4_l3(...) // update ttl and mac addresses
| ctx_redirect(ctx, HOST_IFINDEX, 0) // redirect to cilium_host
pod to service (clusterIP)
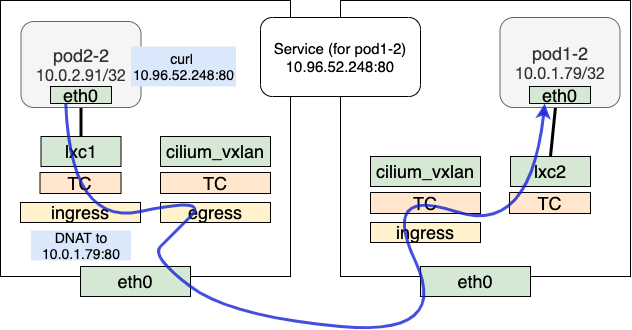
The overall process for communication from pod to service is similar to that of pod-to-pod. In the TX phase, the difference lies in the handling of __tail_handle_ipv4, where the BPF map cilium_lb4_services_v2 is checked for the corresponding service. If a match is found, the process enters the DNAT phase. In this phase, packets pass through CT, then we query the BPF map cilium_lb4_backends_v2 to determine which backend packet should go. Once a backend real server is selected, the clusterIP is replaced with the actual IP of the backend.
root@cilium-worker:/home/cilium# cilium map get cilium_lb4_services_v2
Key Value State Error
10.96.0.1:443 0 1 (1) [0x0 0x0] sync
10.96.0.10:53 0 2 (2) [0x0 0x0] sync
10.96.0.10:9153 0 2 (3) [0x0 0x0] sync
10.96.52.248:80 0 1 (5) [0x0 0x0] sync
root@cilium-worker:/home/cilium# cilium map get cilium_lb4_backends_v2
Key Value State Error
4 ANY://10.0.2.230:53 sync
5 ANY://10.0.2.230:9153 sync
7 ANY://10.0.1.79:80 sync
1 ANY://172.18.0.4:6443 sync
2 ANY://10.0.1.9:53 sync
3 ANY://10.0.1.9:9153 sync
After DNAT, the subsequent forwarding processes are similar to pod-to-pod.
// bpf_lxc.c
handle_xgress(struct __ctx_buff *ctx)
| ep_tail_call(ctx, CILIUM_CALL_IPV4_FROM_LXC)
| tail_handle_ipv4(struct __ctx_buff *ctx)
| __tail_handle_ipv4(ctx)
| lb4_lookup_service(...) // lookup service map
| lb4_local(...) // handle CT & DNAT
| tail_handle_ipv4_cont(struct __ctx_buff *ctx)
| handle_ipv4_from_lxc(ctx, &dst_id)
| encap_and_redirect_lxc(...) // tunnel_endpoint is fetched from cilum_ipcache map
| __encap_and_redirect_with_nodeid(...)
| __encap_with_nodeid(...)
| ctx_redirect(ctx, ENCAP_IFINDEX, 0) // redirect to vxlan netdev
On receiving the response, the RX side performs reverse NAT, which replaces source IP with clusterIP, then redirects to destination interface.
// Call stack
| tail_ipv4_to_endpoint
| ipv4_policy
| lb4_rev_nat // reverse nat
| map_lookup_elem(&LB4_REVERSE_NAT_MAP, ...) // lookup reversed nat map
| __lb4_rev_nat // replace source IP
| redirect_ep(ctx, ifindex, from_host) // redirect to dest iface
pod to external
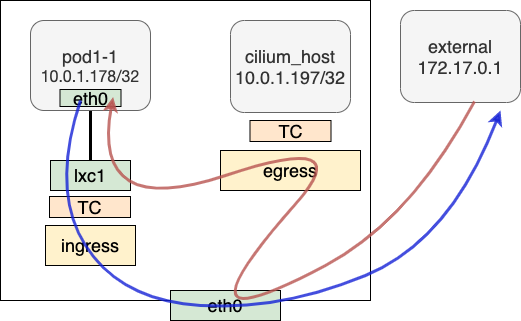
Packets from pod to external (outside cluster) are processed by tc ingress at lxc. ipv4_l3 performs regular layer 3 logic. Then they are sent to the kernel stack. After masquerade by kube-proxy, packets are sent to the wire.
handle_xgress(struct __ctx_buff *ctx)
| ep_tail_call(ctx, CILIUM_CALL_IPV4_FROM_LXC)
| tail_handle_ipv4(struct __ctx_buff *ctx)
| __tail_handle_ipv4(ctx)
| tail_handle_ipv4_cont(struct __ctx_buff *ctx)
| handle_ipv4_from_lxc(ctx, &dst_id)
| ret = encap_and_redirect_lxc(...)
| if (ret == DROP_NO_TUNNEL_ENDPOINT) goto pass_to_stack
| pass_to_stack: ipv4_l3(...)
| return to stack
At RX side, when receiving the response, the host conducts reverse address translation in the context of the masquerade. According to the host routing table, packets are sent to cilium_host. The attached BPF program checks the incoming packets are from external and then redirects to the corresponding lxc1 of pod1-1
Conclusion
This article provides a deep dive into how Cilium datapath handles network connectivity through source code. It needs a certain level of background knowledge of BPF and the kernel. We will explore more in future articles.
Reference
1. BPF and XDP Reference Guide
2. Life of a Packet in Cilium: Discovering the Pod-to-Service Traffic Path and BPF Processing Logics